In paper1 Generalizable Imitation Learning from Observation via Inferring Goal Proximity, the idea of task structure/task information is proposed without further citation or reference.
This high-level task structure generalizes to new situations and thus helps us to quickly learn the task in new situations.
As for current AIRL methods:
However, such learned reward functions often overfit to the expert demonstrations by learning spurious correlations between task-irrelevant features and expert/agent labels CoRL21, and thus suffer from generalization to slightly different initial and goal configurations from the ones seen in the demonstrations (e.g. holdout goal regions or larger perturbation in goal sampling).
In the experiment part of the paper, there are 3 types of goal-directed tasks: navigation, locomotion, and robotic manipulation.
As for experiment setup:
expert demonstrations are collected from (1) only a fraction of the possible initial and goal states (e.g. 25%, 50% coverage) and (2) initial states with smaller amounts of noise.
(1) mimics that expert might generate demo in similar but different setting. (2) makes agent to encounter greater noise in real task.
To better explain the idea of experiments, we may exam the idea of designing navigation task. Shortest-path algorithms are used to generate different trajectories as experts and the starting/ending points vary. Experts’ trajectories covers only x% of all possible starting/ending points. And the agent is tested on full distribution.
In paper2 XIRL: Cross-embodiment Inverse Reinforcement Learning, the idea of cross embodiment is different from the “generalization” idea in paper1.
Specifically, we present a self-supervised method for Cross embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences
Just jump to the experiment part (X-MAGICAL benchmark):
In this work, we consider a simplified 2D equivalent of a common household robotic sweeping task, where in an agent has to push three objects into a predefined zone in the environment (colored in pink). We choose this task specifically because its long-horizon nature highlights how different agent embodiments can generate entirely different trajectories. The reward in this environment is defined as the fraction of debris swept into the zone at the end of the episode.
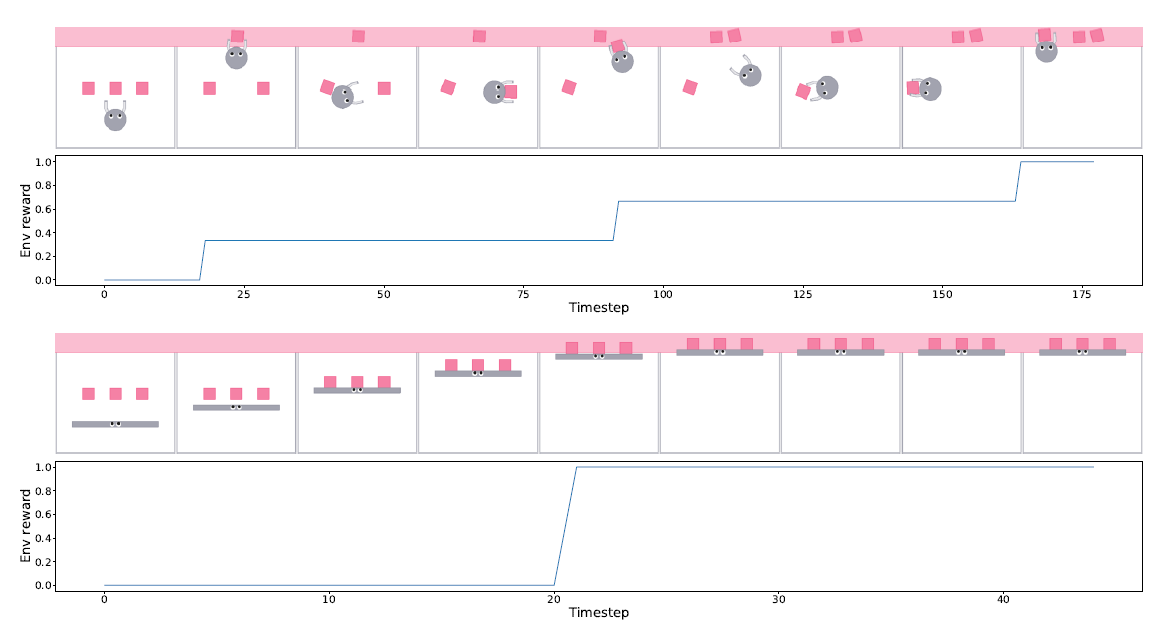
If need to compare, the rewarding is the same in both paper1 and paper2. Paper1 provides experts with different goals(ending point) while paper2 provides experts with different embodiment(but same goal?). Also, XIRL did work on learning from human(TCC is really super powerful):
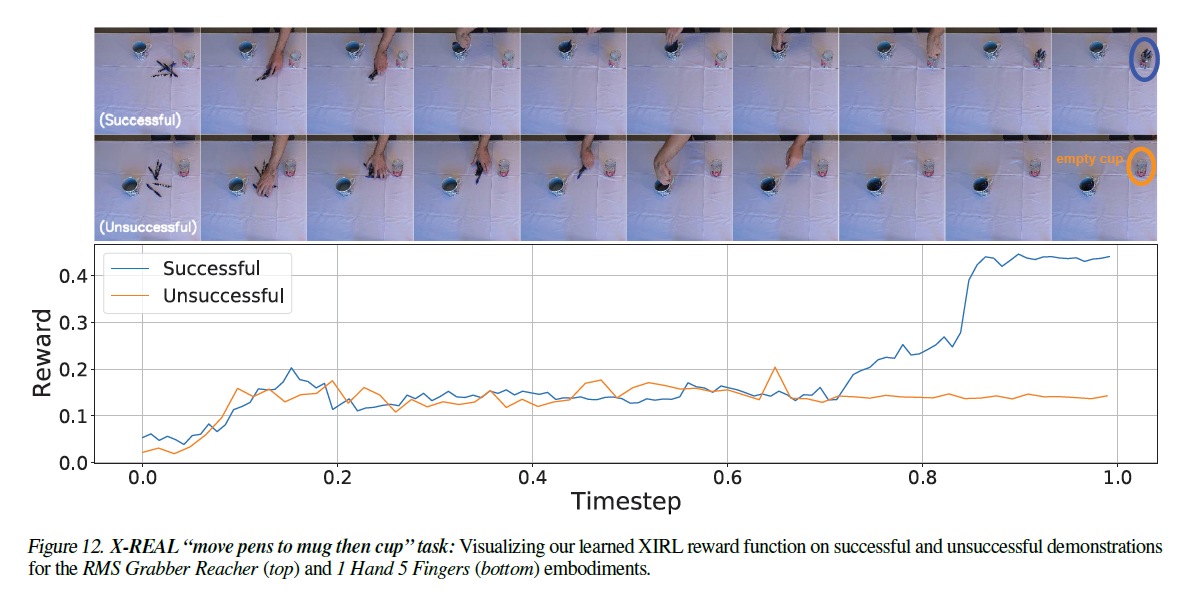
In paper3 Cross-domain Imitation from Observations, we see similar setting in paper2(notice that paper3 utilize something called proxy task).
Dynamics-Reacher2Reacher (D-R2R): Agent domain is the 2-link Reacher and expert domain is the Friction modified 2-link Reacher, created by doubling the friction co-efficient of the former. The proxy tasks are reaching for M goals and the inference tasks are reaching for 4 new goals, placed maximally far away from the proxy goals. See the supplementary for more details on goal placement.

I guess, paper2/paper3 have major contribution in utilizing “unaligned unpaired” trajectories.