By Yinggan XU Dibbla
This is generated by a previous courses (not included in Lee’s 2022 series), video can be found: CNN
The motivation is that we can of course use MLP to find a function such that we do image classification etc. However, it’s not necessary and not efficient due to the tremendous number of parameters. We are going to use the properties of images themselves.
Before that, we need to know the structure of a picture. For a RGB picture, each pixel in the whole picture is determined by 3 values: Red, Green, Blue (RGB), and R,G,B are called channels. So actually, we are given a 3 layer matrix when we are given a RGB picture.
Recap how we, as human, recognize a bird🐦. We recognize certain patterns: the beak, the feather, the claw, then we draw the conclusion: Yes, it is a bird.
CNN does pretty much the same thing based on several observation:
- Neurons does not have to see the whole picture
- Same pattern can appear in different places
Based on these observations, we modify the network to make it simpler:
Simplification 1
Unlike MLP where every neuron takes in the whole picture, CNN uses receptive field to make a neuron only see certain part of the picture.
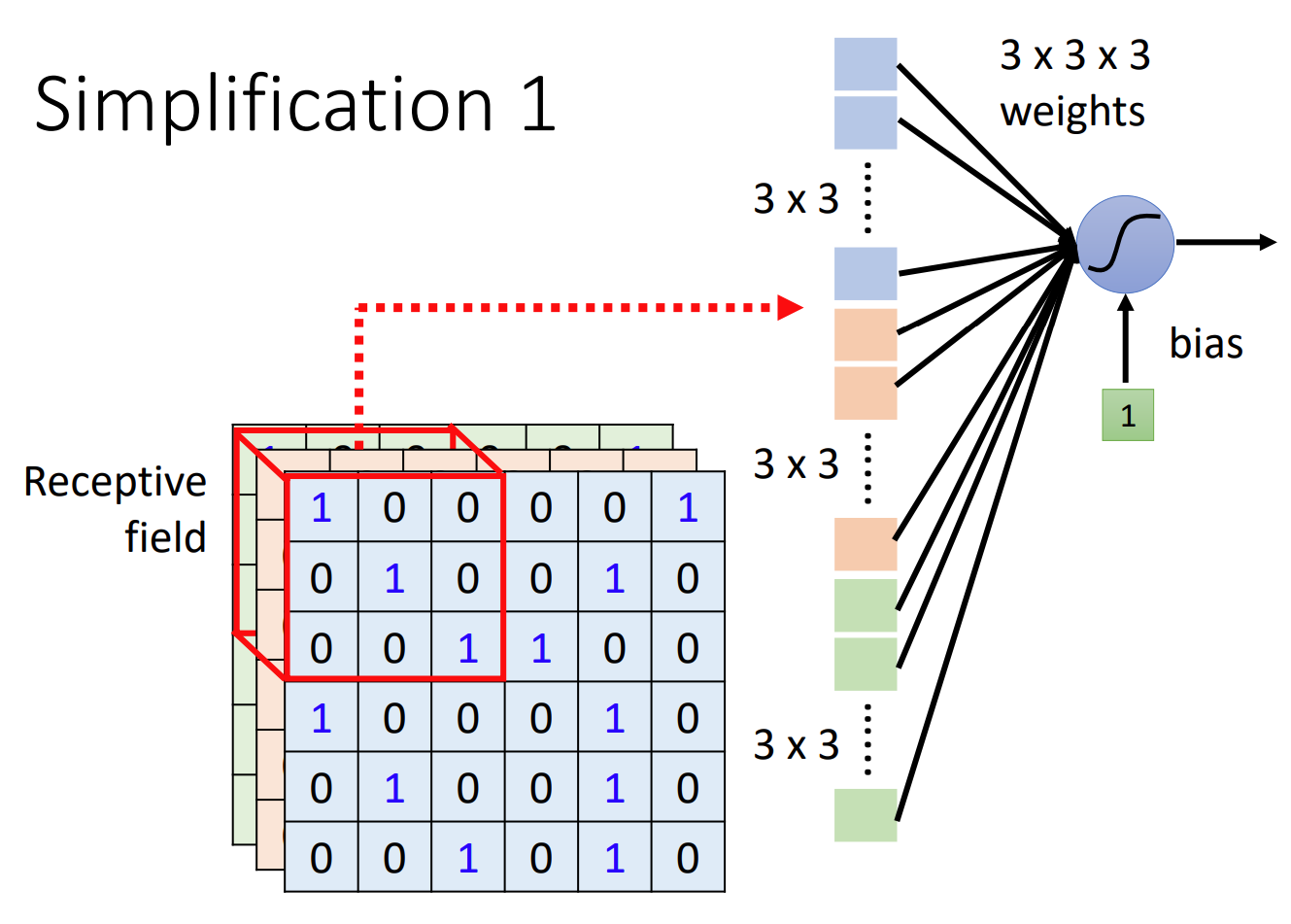
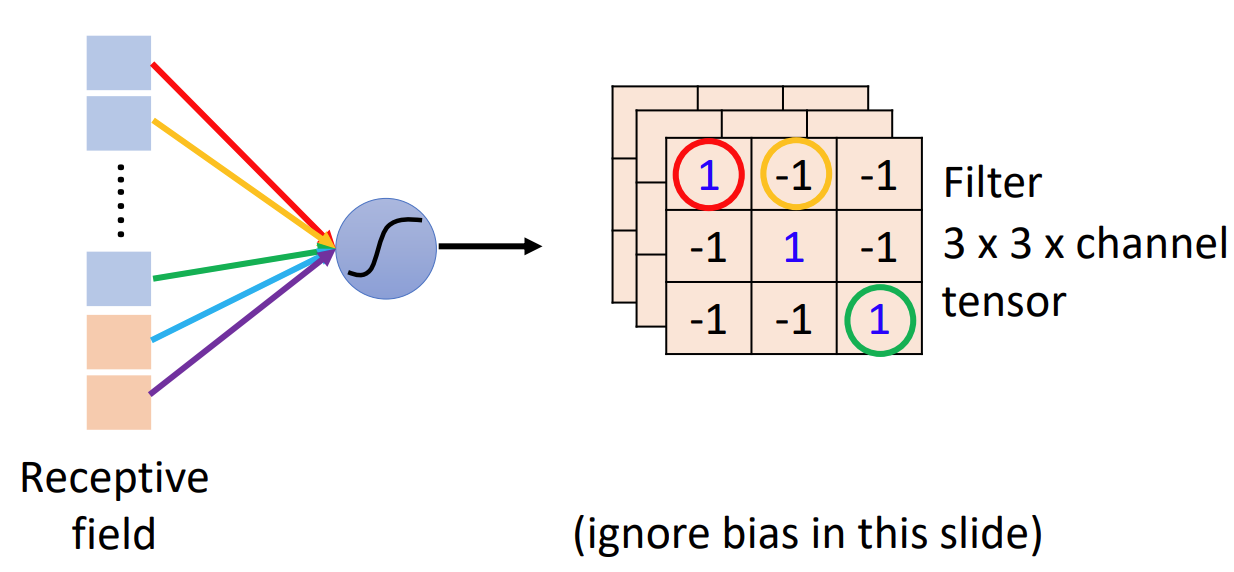
Like the picture you see, we use a neuron to monitor a part of the picture. In the example, it is 3x3x3, 3 channels with 3x3 area. We stretch the area in to a (3x3)x3 1-dimensional vector and use it as the input for neuron.
Notice that
- Receptive field can be overlapped
- Multiple receptive field can overwatch the same area
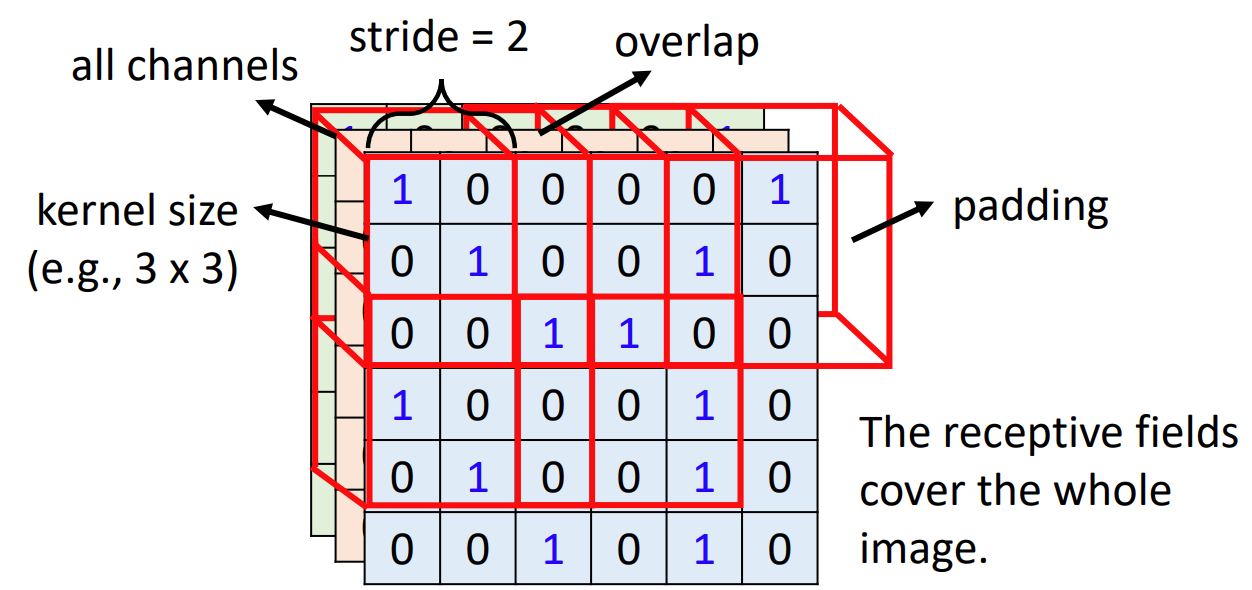
A ‘classical’ setting of receptive field is as following:
- See all channel
- Not large kernel size (the size of area neuron watches)
- Multiple neurons for single receptive field (e.g. 64)
- Stripe for overlap
- Zero Padding
Simplification 2
Recap the bird🐦 recognition. We can see that the beak-detection neuron can be applied to anywhere in the picture to detect beaks. So the idea is to share parameters in the same-type-feature recognition neuron.
The parameter sharing groups are called ‘filters’
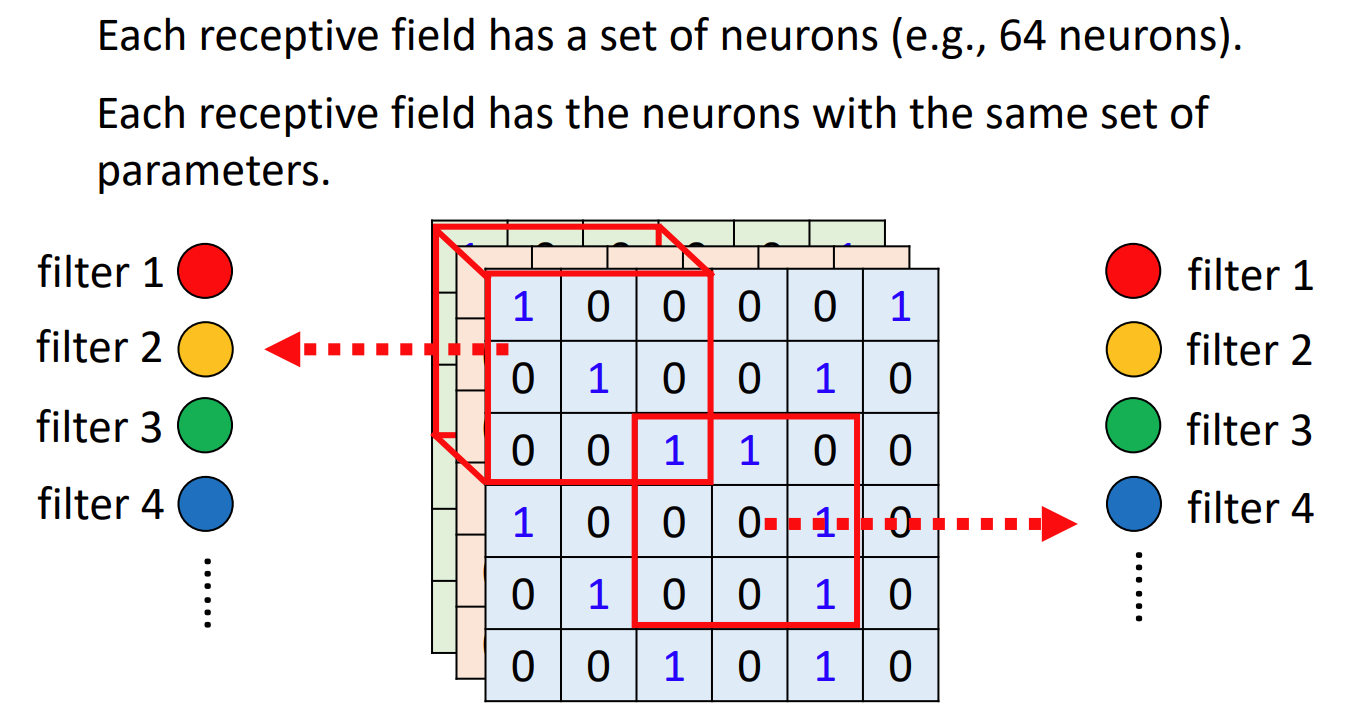
From another point of view
We have many ‘filters’. In our example, they are all 3x3xChannel tensor. Filter’s weights are learnt parameters. Filter multiplies receptive field (multiply one by one and sum up). Every filter gives a feature matrix of whole picture, called feature map.
Two stories are equal
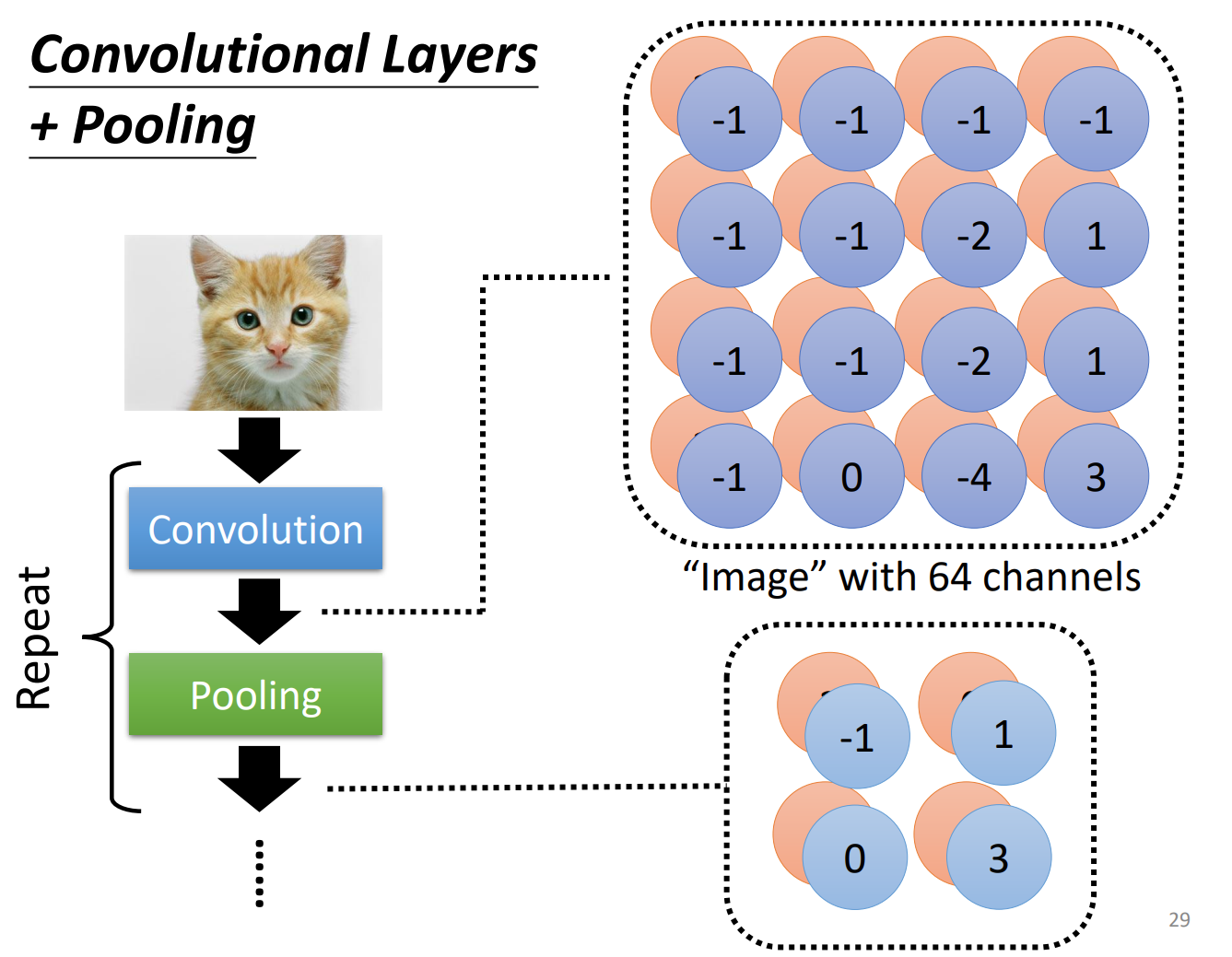
One more observation: Pooling
It is like a ReLU or non-learnt operation following convolutional layer. It is based on the observation that subsampling does not change the information. Pooling reduces the computation cost. It is not necessary.
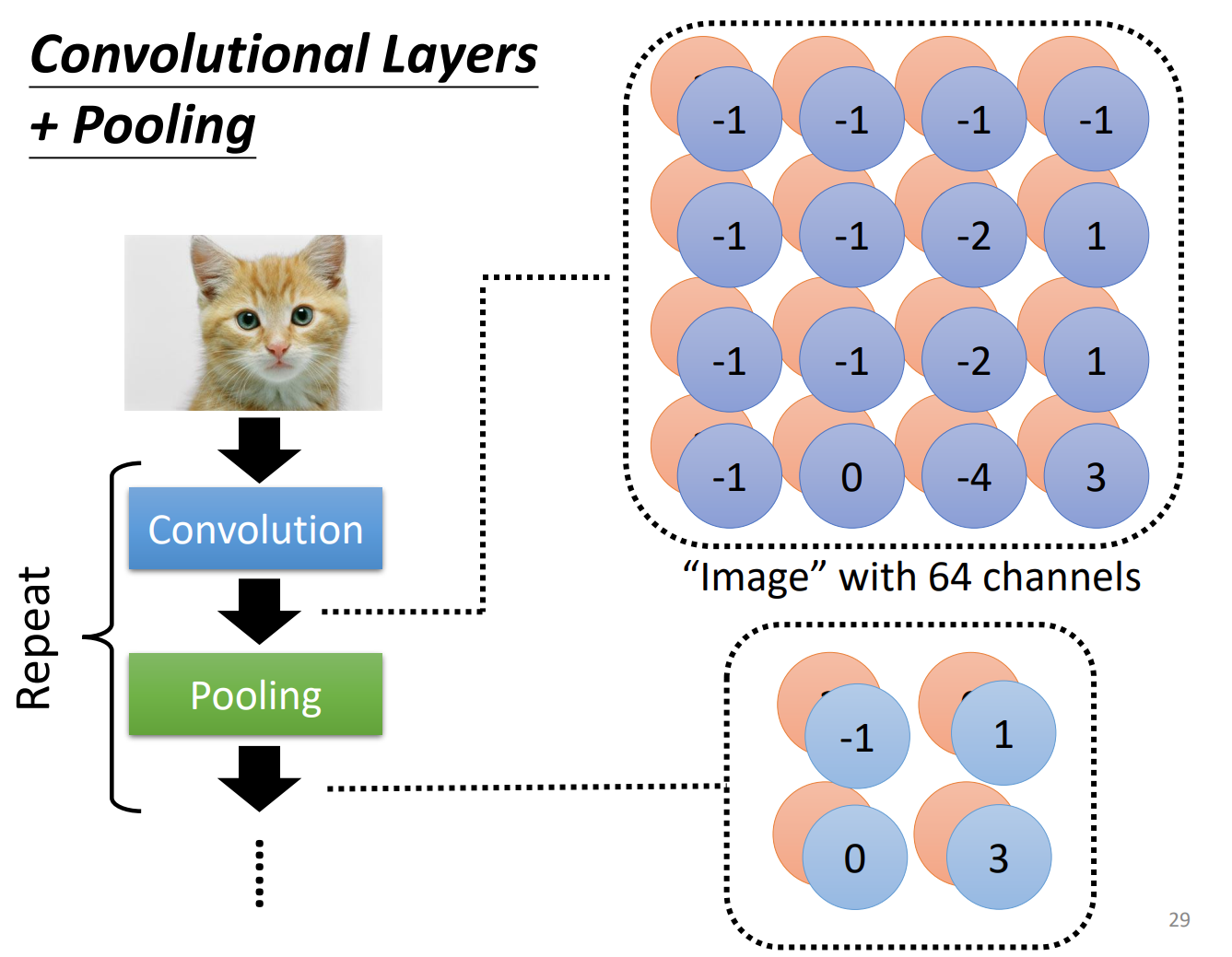
We finally use a MLP connected to the output of CNN layers, to output classification and other goals